After defining the necessary signatures, we can create corresponding
functors. In order to let the readers more easily understand the system,
we describe the functors from the top level to the bottom level. These are
also the steps when we define functors.
The Prelude Functor
Now, let's see the definition of functor Prelude:
functor Prelude(): PRELUDE =
struct
val codeof0 = ord "0"
val codeof9 = codeof0 + 9
fun charofdigit n = chr(n+codeof0)
fun stringofnat n
= if n<10
then charofdigit n
else stringofnat(n div 10)^charofdigit(n mod 10)
fun stringofint n = if n<0
then "~"^stringofnat(~n)
else stringofnat n
(* read data from a file and output as string *)
fun file x = input(open_in x,10000)
(* display the error message *)
exception Error
fun say (msg: string)
= (print msg; print "\n"; raise Error)
fun error msg = say msg
(* check whether b is the element of a list *)
fun member (a :: x) b
= if a = b then true else member x b
| member [ ] b = false
end
Functor Prelude defines some functions and uses signature PRELUDE as its result signature. Function file reads a file name as a string and outputs the file contents as a long string. For example, we have a file called ``test.tst'' which contains a Macro COSY program:

when we use the function file:
- file "test.tst";
the output will be:
val it = "program array a(3) endarray path #i:1,3,1[a(i);@] end
endprogram "
The function error is to display the error message, function member
is to check whether the element is the member of the list, function
stringofint is to change the integer into string.
The COSY functor
The functor Cosy uses signature COSY as its result signature:
functor Cosy(): COSY =
struct
datatype mprogram = Program of mprogrambody
and mprogrambody = Programbody1 of mpath
| Programbody2 of mprocess
| Programbody3 of bodyreplicator
| Programbody4 of collectivisor * mprogrambody
| Programbody5 of mpath * mprogrambody
| Programbody6 of mprocess * mprogrambody
| Programbody7 of bodyreplicator * mprogrambody
...
and integer = Integer of int
and name = Name of string;
end
Now, let's see how the grammars are translated into concrete datatypes. At first, because most parser generating tools are of a recursive form, so, we translate the Syntax of General COSY Macro Notation as given in [JL92] p.459 to recursive datatypes representing the original to the format using quoted terminals. We also use the <> to indicate the non-terminal symbols. For example, we translate the grammars of mprogram and mprogrambody from:
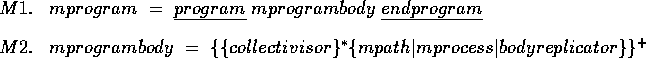
into:
M1. <mprogram> = "program" <mprogrambody> "end"
M2. <mprogrambody> = <mpath>
| <mprocess>
| <bodyreplicator>
| <collectivisor> <mprogrambody>
| <mpath> <mprogrambody>
| <mprocess> <mprogrambody>
| <bodyreplicator> <mprogrambody>
When we translate the grammars, most of the rules are straight forward. But some of them are not. From the Syntax of General COSY Macro Notation as given in [JL92]p.459, we can see that spaces are included inside the grammars. But the lexical analyzer which we use gets rid of all spaces during analysis. Due to this reason, we do some modifications and introduce some extra rules in order to avoid the spaces. For example, the rule M9.2 in [JL92] p.459 is

that means dim is either space(empty) or iexpr. When we translate this rule, we remove the space:
M9.2. <dim> = <iexpr>
and when we apply it to the other rules, for instance,
![]()
we introduce an extra rule to it:
M9. <distributor> = <sep> <dim> <range> "[" <msequence> "]"
| <sep> <range> "[" <msequence> "]"
From above we can see explicitly that the distributor is with either <dim> or not.
We also need to introduce extra rules for some original rules when we translate. For example, the rule M2.3 in [JL92] p.459 is
![]()
When we translate it into the recursive datatype, we introduce extra rules for it:
M2.3. <replardecl> = <range_spec> "[" <replardeclbody> "]"
M2.3.1 <replardeclbody> = <replardecl>
| <subsevents>
| <replardeclbody> <replardecl>
| <replardeclbody> <subsevents>
The Lexical Analyzer Functor
The functor Lex uses signature LEX as its result signature and uses PRELUDE as a signature of its parameter structure:
functor Lex (structure PRLD: PRELUDE): LEX =
struct
val err_lex = ref 0
datatype token = Operation of string
| Symbol of string
| Number of int
val keyword
= PRLD.member ["program","endprogram","path",
"process","end","array","endarray"]
fun keycheck s
= if keyword s then Symbol s else Operation s
fun digit d = ord d >= ord "0" andalso ord d <= ord "9"
fun letter s
= (ord s >= ord "A" andalso ord s <= ord "Z") orelse
(ord s >= ord "a" andalso ord s <= ord "z")
fun letdigetc a = if letter a then true
else if digit a then true
else PRLD.member ["'","_"] a
val layout = PRLD.member [" ","\n","\t"]
val symbolchar
= PRLD.member ["&","*","[","]",",",";",":","#",
"|","@","div","+","**","-","~"]
fun intofdigit d = ord d - ord "0"
fun lexanal [ ] = [ ]
| lexanal (a::x)
= if layout a then lexanal x else
if a = "(" then Symbol "(" :: lexanal x else
if a = ")" then Symbol ")" :: lexanal x else
if a = "-" then getnum_minus 0 x else
if a = "~" then getnum_minus 0 x else
if letter a then getword [a] x else
if digit a then getnum (intofdigit a) x else
if symbolchar a then getsymbol [a] x else
PRLD.error ("Lexical Error : unrecognized token"
^ a) handle PRLD.Error
=> (err_lex := (!err_lex) + 1; lexanal x)
and getword l [ ] = [keycheck (implode (rev l))]
| getword l (a :: x)
= if letdigetc a then getword (a :: l) x
else keycheck (implode (rev l)) :: lexanal (a :: x)
and getsymbol l [ ] = [Symbol (implode (rev l))]
| getsymbol l (a :: x)
= if l = ["*"] andalso a = "*"
then Symbol "**" :: lexanal x
else Symbol (implode (rev l)) :: lexanal (a :: x)
and getnum n [ ] = [Number n]
| getnum n (a :: x)
= if digit a
then getnum (n * 10 + intofdigit a) x
else Number n :: lexanal (a :: x)
and getnum_minus n [ ] = [Number (0-n)]
| getnum_minus n (a :: x)
= if digit a
then getnum_minus (n * 10 + intofdigit a) x
else Number (0-n) :: lexanal (a :: x)
end
Inside the functor, we define a function called lexanal. As the name indicates it acts as a lexical analyzer. It reads the COSY program as a string list and tokenizes the whole program from a string list into a token list. From its result signature we can see that its type is:
lexanal : string list -> token list
The lexical analyzer we designed uses the idea of parser builders of Chris Reade from his book, [Rea89] pp.220-222, and we did some expansion. At first, we need to define a type token to distingush the lexical items:
datatype token = Operation of string
| Symbol of string
| Number of int
The datatype token has three constructors. Constructor Operation identifies the non-terminal symbols of the Macro COSY program such as the event ``write'', ``read'' and the variable name such as ``i'',``j''. Constructor Symbol classifies the terminal symbols of the Macro COSY program such as , and some symbol characters such as ``('' and ``)''. Constructor Number identifies both positive and negative integers.
Let's use the following example to see how the lexical analyzer classifies lexical items into Operation, Symbol and Number:
![]()
the lexical analyzer will break this up into a token list:
[Symbol "program",Symbol "array",Operation "d",Symbol "(",
Number 3,Symbol ")",Symbol "endarray",Symbol "path",Symbol "#",
Operation "i",Symbol ":",Number 1,Symbol ",",Number 3,Symbol ",",
Number 1,Symbol "[",Operation "a",Symbol "(",Operation "i",
Symbol ")",Symbol ",",Symbol "@",Symbol "]",Symbol "end",
Symbol "endprogram"]
Now, let's use the graph to see how the lexical analyzer works.
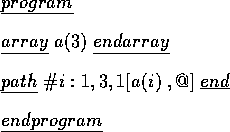
Figure 3.1 illustrates that the state lexanal is a initial state and the next state is determined by the next input symbol. The control characters and spaces are ignored and the state is left as lexanal. Similarly, the pathentheses ``('' and ``)'' generate a token without changing the state. If a digit is encountered while in the lexanal state, the state will be switched to the state getnum which deals with subsequent digits and will return to the state lexanal when a non-digit character is encountered. If a symbol ``'' or ``-'' is encountered while in the lexanal state, like the state getnum, the state will be changed to the state getnum_minus which deals with subsequent digits and returns to the state lexanal when a non-digit is encountered. If an alphabetic letter is encountered in the lexanal state, then the state is changed to the state getword and it is maintained when letters or digits or primes or underscores are encountered until other character occurs. Before going back to the state lexanal, it will check whether the word which just got is a keyword. If it is a keyword, then the word is a terminal symbol. Otherwise, it is a simple operation. For example:
val keyword = member ["program","endprogram","path","process","end",
"array","endarray"]
fun keycheck s = if keyword s the Symbol s else Operation s
After completed checking, it will return to the state lexanal. The last state is getsymbol state. If a symbolic character is encountered such as a comma or a semicolon, the lexanal state will be changed to this last state. If other characters are not recognized by the analyzer, the analyzer will display a error message.
When the lexical analyzer finished analyzing, if errors are found
during analyzing, for instance, control characters and unprintable
characters, it will prompt an error message to tell the user that the
analysis failed. The user can re-apply the
program to the analyzer
again when the errors have been fixed. If there is no error to be
found, the analyzer will output a token list.
The Parser Builder Functor
The functor Parser_build uses signature PARSER_BUILDER as its result signature and uses LEX as a signature of its parameter structure:
functor Parser_builder(structure LX: LEX): PARSER_BUILDER =
struct
structure LX= LX
datatype 'a possible = Ok of 'a
| Fail
fun pair x y = (x, y)
infixr 4 <&>
infixr 3 <|>
infix 0 modify
fun (parser1 <|> parser2) s
= let fun parser2_if_fail Fail = parser2 s
| parser2_if_fail x = x
in parser2_if_fail (parser1 s) end
fun (parser modify f) s
= let fun modresult Fail = Fail
| modresult (Ok(x, y)) = Ok(f x, y)
in modresult (parser s) end
fun (parser1 <&> parser2) s
= let fun parser2_after Fail = Fail
| parser2_after (Ok(x1, s1))
= (parser2 modify (pair x1)) s1
in parser2_after (parser1 s) end
fun emptyseq s = Ok([], s)
fun consonto x a = a :: x
fun optional pr = (pr modify (consonto []))
<|> emptyseq
fun number (LX.Number n::s) = Ok(n, s)
| number other = Fail
fun literal a (LX.Symbol x::s)
= if a = x then Ok(x, s) else Fail
| literal a other = Fail
fun operation (LX.Operation x::s) = Ok(x,s)
| operation other = Fail
end
When we create the parser builders, we also use ideas of Chris Reade from
his book [Rea89]pp.213-219.
The reason why we use his ideas is not that we are lazy. It is because
that his parser builders are general and generally used in programs
involving SML.
Firstly, we define a datatype:
datatype 'a possible = Ok of 'a
| Fail
that allows a parser to return Ok (tree,token list) if there is no error during parsing, to return Fail if there is error while parsing.
Inside the functor we can see that the parser builders 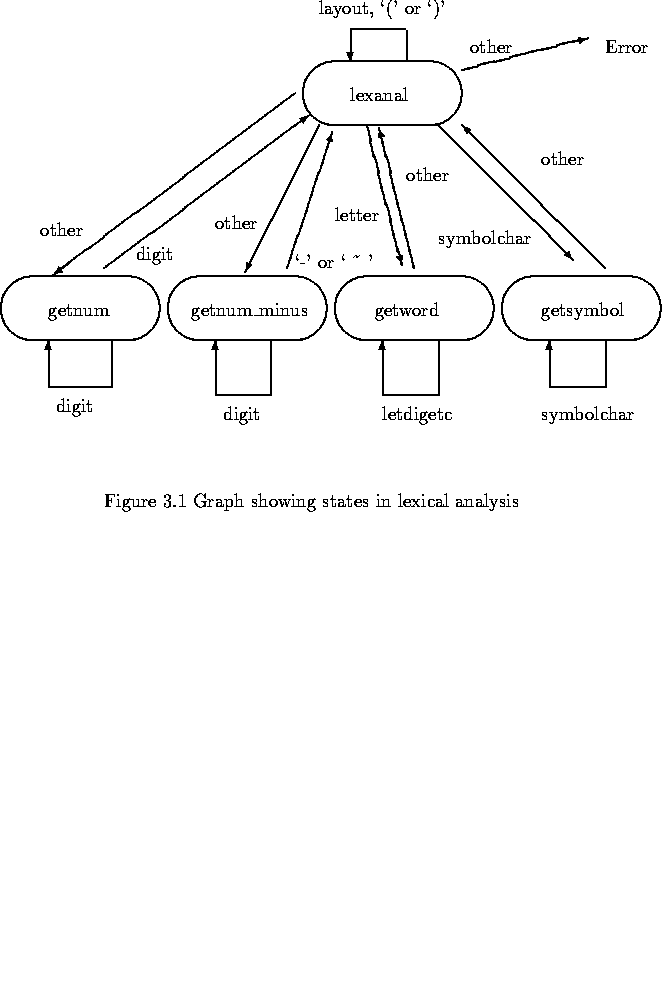 and <|> are
right associative infix operators and modify is left associative.
is specified that has the highest precedence among them and <|> is in the
middle and modify has the lowest precedence. The parser formed by parser
modify f is defined to try the parser on the argument and then apply the
function modresult which is defined locally to the result. If the
intermediate result was Fail, this would be left unchanged. If the
result was successful, the first component of the result pair would be
changed using f. The parser formed by parser1 <|> parser2 is
defined to try parser1 on the argument and pass the result to the
locally defined function parser2_of_fail which would simply return
the same result if it was successful. If the first result was Fail,
the parser2 would be tried on the original argument. If both results
were Fail, the final result would be Fail. The parser formed
by parser1 <\&> parser2 is defined to apply parser1 to the
argument and uses the function parser2_after which is defined locally
to leave failures as failures, but to pick up the unconsumed token list
in the successful case on the result. The second parser parser2 is
used to produce a second result on this token list. ([Rea89] pp.213-219)
and <|> are
right associative infix operators and modify is left associative.
is specified that has the highest precedence among them and <|> is in the
middle and modify has the lowest precedence. The parser formed by parser
modify f is defined to try the parser on the argument and then apply the
function modresult which is defined locally to the result. If the
intermediate result was Fail, this would be left unchanged. If the
result was successful, the first component of the result pair would be
changed using f. The parser formed by parser1 <|> parser2 is
defined to try parser1 on the argument and pass the result to the
locally defined function parser2_of_fail which would simply return
the same result if it was successful. If the first result was Fail,
the parser2 would be tried on the original argument. If both results
were Fail, the final result would be Fail. The parser formed
by parser1 <\&> parser2 is defined to apply parser1 to the
argument and uses the function parser2_after which is defined locally
to leave failures as failures, but to pick up the unconsumed token list
in the successful case on the result. The second parser parser2 is
used to produce a second result on this token list. ([Rea89] pp.213-219)
The Parser Functor
The functor Parser uses signature PARSER as its result signature and uses PRELUDE, PARSER_BUILDER, COSY and LEX as signatures of its parameter structures:
functor Parser(structure PRLD: PRELUDE
structure PRSR_BLDR: PARSER_BUILDER
structure CSY: COSY
structure LX: LEX
sharing PRSR_BLDR.LX = LX): PARSER =
struct
structure PRLD = PRLD
structure LX = LX
structure PRSR_BLDR = PRSR_BLDR
structure CSY = CSY
local
open PRLD
open PRSR_BLDR
open CSY
open LX
infixr 4 <&>
infixr 3 <|>
infix 0 modify
fun mprogram1 s = (literal "program" <&> mprogrambody1 <&>
literal "endprogram" modify mp) s
...
and mp (p,(a,e)) = Program a
...
in
fun m_parser x = mprogram1 x
end
end
The task of the parser is to construct a syntax tree using the token list which created by the lexical analyzer.
When the parser builders are created, we can define the parsers for the Macro COSY program based on the grammars and their corresponding datatypes. For example, we have:
M1. <mprogram> = "program" <mprogrambody> "end"
and
datatype mprogram = Program of mprogrambody
In the functor Parser, we define some functions to do parsing according to the given grammar and datatype:
fun mprogram s = (literal "program" <&> mprogrambody <&>
literal "endprogram" modify mp) s
and mp (p,(a,e)) = Program a
In pattern (p,(a,e)) of the function mp, p and e correspond to "program" and "endprogram" and a corresponds to mprogrambody. (For the details of the parsers, please see Appendix B for file name ``nmp_parser.sml'')
After completed parsing, if an error is encountered, the parser will display the error message and let the user check his/her program again. If there is no error to be found, the parser will output an object of type mprogram(syntax tree).
The syntax tree we have right now is only a correct mprogram according
to context-free grammar. So, we need to create some functions to check
whether the syntax tree satifies all the context-sensitive restrictions.
Therefore, we create a functor called Csr. Before creating functor
Csr, we create a functor called Csr_prelude which contains
some functions that are use frequently in functor Csr.
The Prelude of Context-Sensitive Restrictions Functor
The functor Csr_prelude uses signature CSR_PRELUDE as its result signature and uses COSY, LEX and PRELUDE as signatures of its parameter structures:
functor Csr_prelude(structure CSY: COSY
structure LX: LEX
structure PRLD: PRELUDE): CSR_PRELUDE =
struct
structure CSY = CSY
structure PRLD = PRLD
structure LX = LX
open CSY
open PRLD
open LX
val unboundlist = ref [{name=" ", value=0}]
type unbound = {name : string,
value : int}
fun iex1 (Dim(a)) = iex a
and iex (Iexpr1(Integer a)) = a
| iex (Iexpr2(Rangevariable(Name a)))
= getvalue(a,(!unboundlist))
| iex (Plus(a,b)) = (iex a) + (iex b)
| iex (Mult(a,b)) = (iex a) * (iex b)
| iex (Div(a,b)) = (iex a) div (iex b)
| iex (Pow(a,b)) = power((iex a),(iex b))
| iex (Iexpr4(a)) = iex a
| iex other = error "imposible" handle Error => 0
and power(a,b) = if b>1 then a * power(a,(b-1)) else a
(* get the corres ponding value from unbound list *)
and getvalue(a,((l:unbound)::x))
= if a = (#name l) then (#value l) else getvalue(a,x)
| getvalue(a,[]) = cr_unbound_list(a,unboundlist)
(* create unbound list and read the value from keyboard
and return the value *)
and cr_unbound_list(a,unboundlist)
= let val read_value = inp a
in unboundlist
:= (!unboundlist) @ [{name=a,value=read_value}];
read_value
end
(* input integer from keyboard *)
and inp (msg:string)
= (print ("Please input the INTEGER value of " ^ msg ^ ": ");
inp1(lexanal(explode(input_line(std_in))),msg))
and inp1 ([Number a],msg) = a
| inp1 (other,msg) = error "Error !!!"
handle Error => inp msg
end
The function iex in this functor is to evaluate the expressions such as a+b, a*b, a**b, etc. If function iex finds that the operand is not bound during evaluation, the function getvalue will be called. getvalue will check the unbound list first. If it finds the value of the operand, it will get the corresponding value. Otherwise, it will call the other function cr_unbound_list to require the user to input an integer value from keyboard. Then, append this value and the name of the operand into unbound list. The structure of the unbound list is:
type unbound = { name : string, value : int }
where name stores the variable name, value stores the bound value.
For example:
![]()
When the program finds that n is an unbound variable, it will prompt a message:
Please input the INTEGER value of n :
Suppose the we enter an integer 3, the unbound table will has the value:
[{name="n",value=3}]
We can use this table during checking. For example, while checking the bodyreplicator:

the program will check the unbound table and retrieves the value of n. So, the bodyreplicator becomes:
![]()
The Context-Sensitive Restrictions Functor
The functor Csr uses signature CSR as its result signature and uses COSY, CSR_PRELUDE and PRELUDE as signatures of its parameter structures:
functor Csr(structure CSY: COSY
structure CSR_PRLD: CSR_PRELUDE
structure PRLD: PRELUDE
sharing CSR_PRLD.CSY = CSY ): CSR =
struct
structure CSY = CSY
structure CSR_PRLD = CSR_PRLD
structure PRLD = PRLD
val err_cnt = ref 0;
type bound = {pos : int,
lower : int,
upper : int,
step : int}
type Arraytable = {name : string,
dim : int,
value : bound list}
type unbound = {name : string,
value : int}
...
local
...
fun mkt (Program(a)) = mpbody a
...
in
fun mktbl x = mkt x
end
local
...
fun cres1 ((a:Arraytable)::x)
= if (cres11 (#value a)) then cres1 x
else (error ("Array '" ^ (#name a) ^
"': upperbound is smaller then lowerbound.")
handle Error => (err_cnt:=(!err_cnt)+1; cres1 x))
| cres1 [] = true
...
in
fun crest1 x = cres1 (mktbl x)
end;
local
...
fun cres2 ((a:Arraytable)::x) l
= if member l (#name a)
then error ("The identifier '"
^ (#name a) ^ "' is duplicate")
handle Error
=> (err_cnt:=((!err_cnt) + 1); cres2 x l)
else cres2 x (l @ [#name a])
| cres2 [] l = true
in
fun crest2 x = cres2 (mktbl x) []
end;
local
...
fun cres3 (Program(a)) = mpbody a
...
in
fun crest3 x = cres3 x
end;
local
...
fun ires1 (x,b::y)
= if member x b then error
"the index and range variable are using the same name"
handle Error => (err_cnt := (!err_cnt) + 1; true)
else ires1 (x,y)
| ires1 other = true
in
fun irest1 x = ires1 ((Rrdt1 x),(Rrdt2 x))
end
local
...
fun ires2 (Program(a)) = mpbody a 1 1
...
in
fun irest2 x = ires2 x
end
local
...
fun brest (Program(a)) = mpbody a 1
...
in
fun brrest x = brest x
end;
local
...
fun rres11 (Program(a)) = mpbody a 1 1
...
in
fun rrest11 x = rres11 x
end;
local
...
fun rres12 (Program(a)) = mpbody a 1
...
in
fun rrest12 x = rres12 x
end;
local
...
fun rres13 (Program(a)) = mpbody a 1
...
in
fun rrest13 x = rres13 x
end;
local
...
fun rres2 (Program(a)) = (mpbody a) (mktbl (Program(a))) 1
...
in
fun rrest2 x = rres2 x
end;
local
...
fun dres1 (Program(a)) = (mpbody a) (mktbl (Program(a))) 1
...
in
fun drest1 x = dres1 x
end;
local
...
fun dres21 (Program(a)) = (mpbody a) (mktbl (Program(a))) 1
...
in
fun drest21 x = dres21 x
end;
local
...
fun dres22 (Program(a)) = (mpbody a) (mktbl (Program(a))) 1
...
in
fun drest22 x = dres22 x
end;
local
...
fun dres3 (Program(a)) = (mpbody a) (mktbl (Program(a))) 1
...
in
fun drest3 x = dres3 x
end;
local
...
fun dres4 (Program(a)) = (mpbody a) (mktbl (Program(a))) 1
...
in
fun drest4 x = dres4 x
end;
local
...
fun dres5152 (Program(a)) = (mpbody a) (mktbl (Program(a))) 1
...
in
fun drest5152 x = dres5152 x
end;
end
Inside the functor Csr, we define a function called mktbl. It establishes a table which stores all information about arrays. The structure of the table is:
type Arraytable = { name : string,
dim : int,
value : bound list }
type bound = { pos : int,
lower : int,
upper : int,
step : int }
where name stores the name of array, dim stores number of the dimensions in the array and value is a list which has the bound value of the array. The type bound consists of pos which stores the position of the dimension, lower which stores the lower bound of that dimension, upper which stores the upper bound of that dimension and step which stores the increasing step. For example:
![]()
After running the mktbl function, the Arraytable will contain:
[{name="a",dim=1,value=[{pos=1,lower=1,upper=3,step=1}]},
{name="b",dim=2,value=[{pos=1,lower=2,upper=4,step=1},
{pos=2,lower=1,upper=4,step=1}]},
{name="c",dim=1,value=[{pos=1,lower=1,upper=5,step=2}]}]
We can make use of the array table while checking the restrictions.
Inside the functor Csr, we also define some functions which check if the COSY program satisfies the Context-Sensitive Restrictions given in [JL93] pp.460-461. Each restriction has its own function. For instance, we have a Macro COSY program as following:
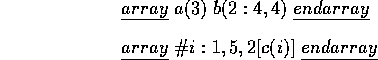
When we parse this program, the parser outputs a syntax tree without any error, but when we use rrest2 to check this syntax tree, an error message occurs. This is because the program violates the context-sensitive restriction Rrest2:
From the Macro COSY program we can see that the array a was declared with 3 elements a(1),a(2) and a(3), but the third line of the program

defines a concatenator which generates consecutive sequences from a(1) to a(4). Obviously, a(4) is out of upper bound of the array a. So, this Macro COSY program does not allow to expand.
During the checking period, we use a counter called err_cnt to count how many errors are found. If the function finds an error while checking, the err_cnt will be incremented by one. From the types of the functions we can see that all functions will return a boolean value. When one of the functions found an error, we still set the boolean value to be true in order to let other functions keep on checking until the last function is called. (For more information of the context-sensitive restrictions checking, please see Appendix B - filename ``csr.sml'')
If no error is found, we will pass the syntax tree to expander. Before
expansion, we need to do two things. One is to put all paths in front of
processes. The other one is to transform all distributor subtree into
concatenator subtree. Now, let's create a functor Pfirst first.
The Path First Functor
The functor Pfirst uses signature PFIRST as its result signature and uses COSY and PRELUDE as signatures of its parameter structures:
functor Pfirst(structure CSY: COSY
structure PRLD: PRELUDE): PFIRST =
struct
structure CSY = CSY
val chg=ref 0
local open CSY
fun pf1 (Program(a)) (chg) = Program(pf_mpb a chg)
...
in
fun pathfirst x chg
= let val pff = pf1 x chg
in if (!chg) = 1
then (chg:=0;pathfirst pff chg) else pff
end
end
end
Function pathfirst moves one or more paths to the front of the processes.
x is a syntax tree and chg is a flag. The flag is assigned to
zero initially. When function pathfirst goes through the syntax tree
once, if one or more paths are moved, the flag will be changed to one.
After finish checking the tree, pathfirst will check the value of the
flag chg. If chg is one then pathfirst will go through
the changed syntax tree again. If chg is zero, pathfirst will
quit and output a syntax tree which all the paths are in front of the
processes. (For more information, please see appendix B - filename
"pfirst.sml")
The Transformer Functor
Now, we need to create a functor Transform. It uses signature TRANSFORM as its result signature and uses COSY, PRELUDE, CSR_PRELUDE and CSR as signatures of its parameter structures:
functor Transform(structure CSY: COSY
structure PRLD: PRELUDE
structure CSR_PRLD: CSR_PRELUDE
structure CSR: CSR
sharing CSR.CSY=CSY=CSR_PRLD.CSY): TRANSFORM =
struct
structure CSY = CSY
structure PRLD = PRLD
structure CSR_PRLD = CSR_PRLD
structure CSR = CSR
type bound = CSR.bound
type Arraytable = CSR.Arraytable
local
...
fun trans (Program(a)) = Program(s_mpb a (mktbl(Program(a))))
...
in
fun transform x = trans x
end
end
The function transform will check the whole tree and change all distributor subtrees into concatenator subtrees. For instance, we have a Macro COSY program as follows:
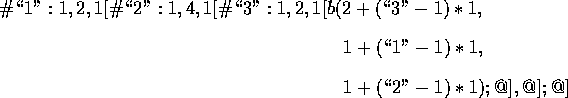
After parsing, we have the syntax tree as follows:
Program
(Programbody4
(Array
(Arraybody1
(Simpleardecl
(Name1 (Name "a"),Simpleardeclbody1 (Iexpr1 (Integer 3))))),
Programbody1
(Path
(Sequence1
(Orelement1
(Gelement3
(Distributor4
(Simicol ";",
Sequence1
(Orelement1
(Gelement1
(Nostar
(Element (Event2 (Name "a"))))))))))))))
After transformation, the distributor is changed to concatenator:
Program
(Programbody4
(Array
(Arraybody1
(Simpleardecl
(Name1 (Name "a"),Simpleardeclbody1 (Iexpr1 (Integer 3))))),
Programbody1
(Path
(Sequence1
(Orelement1
(Gelement2
(Sreplicator1
(Range_spec
(Indexvariable (Name "1"),Iexpr1 (Integer 1),
Iexpr1 (Integer 3),Iexpr1 (Integer 1)),
Concseq
(Sequence1
(Orelement1
(Gelement1
(Nostar
(Element
(Event3
(Name "a",
Meventbody1
(Plus
(Iexpr1 (Integer 1),
Iexpr4
(Mult
(Iexpr4
(Plus
(Iexpr2
(Rangevariable
(Name
"1")),
Iexpr4
(Iexpr1
(Integer
~1)))),
Iexpr1
(Integer
1))))))))))), Simicol ";")))))))))
For more information about the function transform, please see Appendix
B - filename ``transform.sml''.
The Expander Functor
Now, it is the time to define a functor Expand. It uses signature EXPAND as its result signature and uses COSY, PRELUDE, CSR_PRELUDE and CSR as signatures of its parameter structures:
functor Expand(structure CSY: COSY
structure PRLD: PRELUDE
structure CSR_PRLD: CSR_PRELUDE
structure CSR: CSR
sharing CSR.CSY = CSY = CSR_PRLD.CSY): EXPAND =
struct
structure CSY = CSY
structure PRLD = PRLD
structure CSR_PRLD = CSR_PRLD
structure CSR = CSR
type bound = CSR.bound
type Arraytable = CSR.Arraytable
type unbound = CSR.unbound
val unboundlist = ref [{name=" ", value=0}]
local
...
fun expc x = let val mtb = mktbl(x)
in if mtb = [] then () else (print "{\n"; exp1 mtb)
end
...
and ex (Program(a))
= "program "^(ex_mpb a (mktbl (Program(a))))^"endprogram"
...
in
fun expand x = (expc x;ex x)
end;
end
The expand function expands the collectivisors first. Then, it expands the
Macro COSY program which is represented as a syntax tree. It produces an
expanded COSY program which is in the form of a Basic COSY program. (For
more information, please see Appendix B - filename ``expand.sml'')
The COSY Environment Functor
The last functor we need to define is Cosyenv. It combines all functions together. It uses signature COSYENV as its result signature and uses COSY, LEX, PRELUDE, PARSER_BUILDER, PARSER, CSR_PRELUDE, CSR, PFIRST, TRANSFORM and EXPAND as signatures of its parameter structures:
functor Cosyenv(structure CSY: COSY
structure LX: LEX
structure PRLD: PRELUDE
structure PRSR_BLDR: PARSER_BUILDER
structure PRSR: PARSER
structure CSR_PRLD: CSR_PRELUDE
structure CSR: CSR
structure PFRST: PFIRST
structure TRNSFRM: TRANSFORM
structure XPND: EXPAND
sharing PRSR.CSY = XPND.CSY = TRNSFRM.CSY
= CSR_PRLD.CSY = PFRST.CSY = CSR.CSY = CSY
and CSR_PRLD.LX = PRSR_BLDR.LX = PRSR.LX = LX
and PRSR.PRSR_BLDR = PRSR_BLDR): COSYENV =
(* SML provides a sharing mechanism that permits a signature for
a structure containing
struct
structure CSY = CSY
structure LX = LX
structure PRLD = PRLD
structure PRSR_BLDR = PRSR_BLDR
structure PRSR = PRSR
structure CSR_PRLD = CSR_PRLD
structure CSR = CSR
structure PFRST = PFRST
structure TRNSFRM = TRNSFRM
structure XPND = XPND
local
open CSY
open LX
open PRLD
open PRSR_BLDR
open PRSR
open CSR_PRLD
open CSR
open PFRST
open XPND
open TRNSFRM
fun p_c_e x = let val lex_token = lex x
in if !err_lex <> 0
then error ((stringofint (!err_lex)) ^
" lexical error(s) found !!!") handle Error =>""
else let val mp_parser = m_parser lex_token
in if report(mp_parser)
then (csr (report1(mp_parser)))
else error "Parse error(s) found !!!"
handle Error => ""
end
end
and lex x = let
in err_lex := 0; lexanal(explode x) end
and report (Ok (c,[])) = true
| report other = false
and report1 (Ok (c,[])) = c
| report1 other = error "Impossible"
and csr x = let val unbl = [{name=" ",value=0}]
in err_cnt := 0;
unboundlist := unbl;
chg := 0;
crest1 x; (* check Crest1 : upperbound < lowerbound *)
crest2 x; (* check Crest2 : duplicate array name *)
crest3 x; (* check Crest3 : the range is empty *)
irest1 x; (* check Irest1 : index and range use the
same name*)
irest2 x; (* check Irest2 : use index outside the []*)
brrest x; (* check BRrest : the range of bodyreplicator
is empty *)
rrest11 x;(* check Rrest1.1 : inc = 0 *)
rrest12 x;(* check Rrest1.2 : (fi-in) div inc+1 <= 0 *)
rrest13 x;(* check Rrest1.3 : (fi-in) div inc+1 <=0 and
FSTRIP(LSTRIP(t)) = *)
rrest2 x; (* check Rrest2 : range is out of boundary *)
drest1 x; (* check Drest1 : no slice event in
distributor *)
drest21 x;(* check Drest2.1 : do not have the same
sections *)
drest22 x;(* check Drest2.2 : do not have the same
sections at jth dimension *)
drest3 x; (* check Drest3 : more or less than the
number of distributable
dimensions *)
drest4 x; (* check Drest4 : jth dimension is not a
distributable dimension *)
drest5152 x; (* check Drest5.1 and Drest5.2 :
i1,i2,i3 have problems *)
if !err_cnt = 0
then (print "No errrs !!! \n";
expand(transform (pathfirst x chg)))
else (print (stringofint(!err_cnt)
^" error(s) found !!! \n");"")
end
in fun parser_csr_expand x = p_c_e x
end
(* displayer *)
local
...
fun disp x
...
in
fun display x = disp x
end
end
In this functor, we define two functions. One is the most impotant function called parser_csr_expand. It inputs the Macro COSY program as a string and outputs a expanded COSY program as string as well. As the name indicates it parses first, then, checks whether the syntax tree satisfies all context-sensitive restrictions, finally, does the expansion. The other function is display. It displays the expanded COSY program on the screen with a good looking style. Inside this functor, we also use the command ``sharing''. It permits a signature for a structure containing two or more sub-structures to require a type appearing in two or more of its sub-structures to be the same.