Some Theses
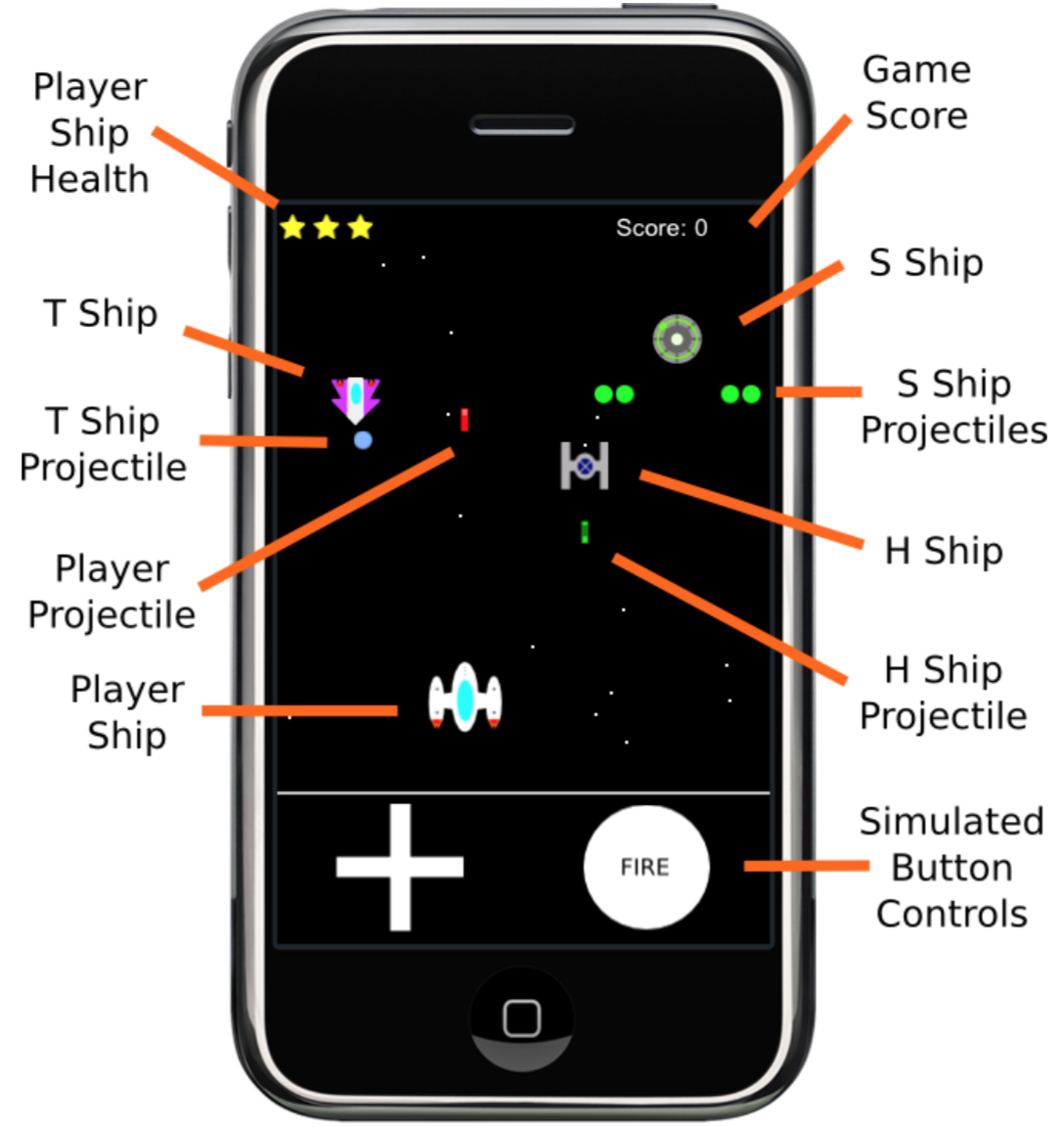 |
Gamification of Mobile Educational Software
By Kevin Browne
March 2016
The overall theme of this thesis is the study of incorporating gamification design approaches in the creation of mobile educational software. The research presented in this thesis focuses on the design and testing of software created to teach introductory computer science and literacy concepts to postsecondary and adult learners. A study testing the relative effectiveness and subjective user enjoyment of different interfaces for a mobile game is also included in this thesis, as the results of the study led to the primary research objectives investigated in further studies. Our primary research objective was to investigate whether using gamification design approaches to mobile educational software could result in student engagement and learning. Our central hypothesis is that gamification design approaches can be used to create engaging and educationally effective mobile educational software. Our secondary research objective is to determine how mobile educational software can be made more or less engaging and educationally effective through gamification design approaches, by trying different approaches, testing the resulting applications, and reporting the findings. Three studies were conducted based on these objectives, one study to teach various computer science concepts to students in a first year computer science course with iPad applications, and two studies which used iPad applications to teach punctuation and homonyms, and improve reading comprehension. The studies document the design of the applications, and provide
analysis and conclusions based on the results of testing. Through the results of these studies we affirm our hypothesis. We make design suggestions for software creators, such as providing corrective feedback to the user. We discuss common themes that emerged across the studies, including how to best use educational software. Finally, as avenues for future work, we suggest investigating the impromptu social effects of using tablet software in a classroom, and the development of a usability testing platform.
Read the entire thesis here. |
Type-Safety for Inverse Imaging Problems
By Maryam Moghadas
September 2012
This thesis gives a partial answer to the question: “Can type systems detect modeling errors in scientific computing, particularly for inverse problems derived from physical models?” by considering, in detail, the major aspects of inverse problems in Magnetic Resonance Imaging (MRI). We define a type-system that can capture all correctness properties for MRI inverse problems, including many properties that are not captured with current type-systems, e.g., frames of reference. We implemented a type-system in the Haskell language that can capture the errors arising in translating a mathematical model into a linear or nonlinear system, or alternatively into an objective function. Most models are (or can be approximated by) linear transformations, and we demonstrate the feasibility of capturing their correctness at the type level using what is arguably the most difficult case, the (discrete) Fourier transformation (DFT). By this, we mean that we are able to catch, at compile time, all known errors in applying the DFT. The first part of this thesis describes the Haskell implementation of vector size, physical units, frame of reference, and so on required in the mathematical modelling of inverse problems without regularization. To practically solve most inverse problems, especially those including noisy data or ill-conditioned systems, one must use regularization. The second part of this thesis addresses the question of defining new regularizers and identifying existing regularizers the correctness of which (in our estimation) can be formally verified at the type level. We describe such Bayesian regularization schemes based on probability theory, and describe a novel simple regularizer of this type. We leave as future work the formalization of such regularizers.
|
 |
Read the entire thesis here.
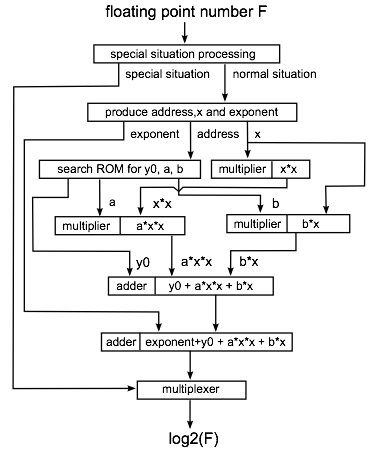 |
A Pipelined, Single Precision Floating-Point Logarithm Computation Unit in Hardware
By Jing Chen
July 2012
A large number of scientific applications rely on the computing of logarithm. Thus, accelerating the speed of computing logarithms is significant and necessary. To this end, we present the realization of a pipelined Logarithm Computation Unit (LCU) in hardware that uses lookup table and interpolation techniques. The presented LCU supports single precision arithmetic with fixed accuracy and speed. We estimate that it can generate 2.9G single precision values per second under a 65nm fabrication process. In addition, the accuracy is at least 21 bits while lookup table size is about 7.776KB. To the best of our knowledge, our LCU achieves the fastest speed at its current accuracy and table size.
Read the entire thesis here. |
Symbolic Generation of Parallel Solvers for Unconstrained Optimization
By Jessica LM Pavlin
May 2012
In this thesis we consider the need to generate efficient solvers for inverse imaging problems in a way that supports both quality and performance in software, as well as flexibility in the underlying mathematical models. Many problem domains involve large data sizes and rates, and changes in mathematical modelling are limited only by researcher ingenuity and driven by the value of the application. We use a problem in Magnetic Resonance Imaging to illustrate this situation, motivate the need for better software tools and test the tools we develop. The problem is the determination of velocity profiles, think blood-flow patterns, using Phase Contrast Angiography. Despite the name, this method is completely noninvasive, not requiring the injection of contrast agents, but it is too time-consuming with present imaging and computing technology.
Our approach is to separate the specification, the mathematical model, from the implementation details required for performance, using a custom language. The Domain Specific Language (DSL) provided to scientists allows for a complete abstraction from the highly optimized generated code. The mathematical DSL is converted to an internal representation we refer to as the Coconut Expression Library. Our expression library uses the directed acyclic graphs as an underlying data structure, which lends itself nicely to our automatic simplifications, differentiation and subexpression elimination. We show how parallelization and other optimizations are encoded as rules which are applied automatically rather than schemes that need to be implemented by the programmer in the low-level implementation. Finally, we present results, both in terms of numerical results and computational performance.
|
 |
Read the entire thesis here.
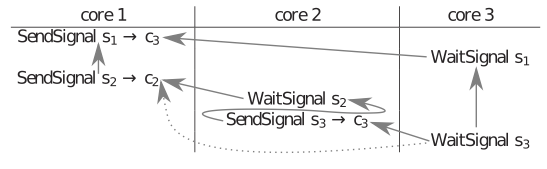 |
Verifying Permutation Rewritable Hazard Free Loops
By Michal Dobrogost
August 2011
We present an extension to the language of Atomic Verifiable Operation (AVOp) streams to allow the expression of loops which are rewritable via an arbitrary permutation. Inspired by (and significantly extending) hardware register rotation to data buffers in multi-core programs, we hope to achieve similar performance benefits in expressing software pipelined programs across many cores. By adding loops to AVOp streams, we achieve significant stream compression, which eliminates an impediment to scalability of this abstraction. Furthermore, we present a fast extension to the previous AVOp verification process which ensures that no data hazards are present in the program's patterns of communication. Our extension to the verification process is to verify loops without completely unrolling them. A proof of correctness for the verification process is presented.
Read the entire thesis here. |
Simulation and Optimal Design of Nuclear Magnetic Resonance Experiments
By Zhenghua Nie
July 2011
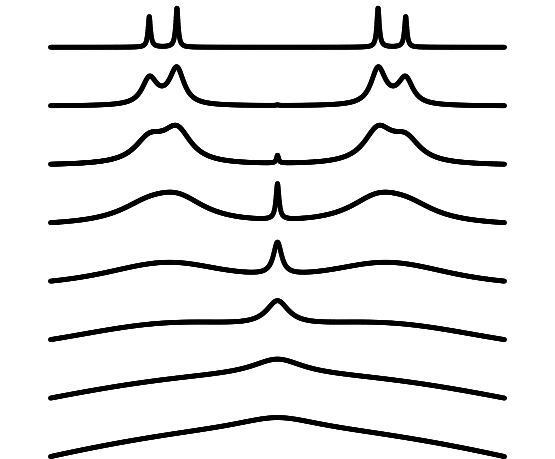
In this study, we concentrate on spin-1/2 systems. A series of tools using the Liouville space method have been developed for simulating of NMR of arbitrary pulse sequences.
We have calculated one- and two-spin symbolically, and larger systems numerically of steady states. The one-spin calculations show how SSFP converges to continuous wave NMR. A general formula for two-spin systems has been derived for the creation of double-quantum signals as a function of irradiation strength, coupling constant, and chemical shift difference. The formalism is general and can be extended to more complex spin systems.
Estimates of transverse relaxation, R2, are affected by frequency offset and field inhomogeneity. We find that in the presence of expected B0 inhomogeneity, off-resonance effects can be removed from R2 measurements, when ||omega||<= 0.5 gamma B1 in Hahn echo experiments, when ||omega||<=gamma B1 in CPMG experiments with specific phase variations, by fitting exact solutions of the Bloch equations given in the Lagrange form.
Approximate solutions of CPMG experiments show the specific phase variations can significantly smooth the dependence of measured intensities on frequency offset in the range of +/- 1/2 gamma B1. The effective R2 of CPMG experiments when using a phase variation scheme can be expressed as a second-order formula with respect to the ratio of offset to pi-pulse amplitude.
Optimization problems using the exact or approximate solution of the Bloch equations are established for designing optimal broadband universal rotation (OBUR) pulses. OBUR pulses are independent of initial magnetization and can be applied to replace any pulse of the same flip angles in a pulse sequence. We demonstrate the process to exactly and efficiently calculate the first- and second-order derivatives with respect to pulses. Using these exact derivatives, a second-order optimization method is employed to design pulses. Experiments and simulations show that OBUR pulses can provide more uniform spectra in the designed offset range and come up with advantages in CPMG experiments.
|
 |
Read the entire thesis here.
 |
A Semi-Definite, Nonlinear Model for Optimizing k-Space Sample Separation in Parallel Magnetic Resonance Imaging
ByQiong Wu
July 2011
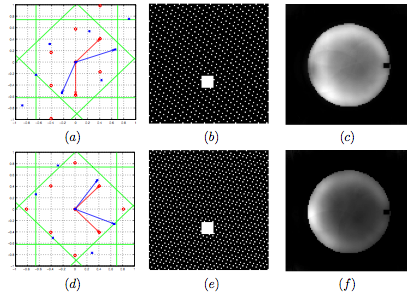
Parallel MRI, in which k-space is regularly or irregularly undersampled, is critical for imaging speed acceleration. In this thesis, we show how to optimize a regular undersampling pattern for three-d\
imensional Cartesian imaging in order to achieve faster data acquisition and/or higher signal to noise ratio (SNR) by using nonlinear optimization. A new sensitivity profiling approach is proposed to pro\
duce better sensitivity maps, required for the sampling optimization. This design approach is easily adapted to calculate sensitivities for arbitrary planes and volumes. The use of a semi-definite, linea\
rly constrained model to optimize a parallel MRI undersampling pattern is novel. To solve this problem, an iterative trust-region is applied. When tested on real coil data, the optimal solution presents \
a significant theoretical improvement in accelerating data acquisition speed and eliminating noise.
|
Read the entire thesis here.
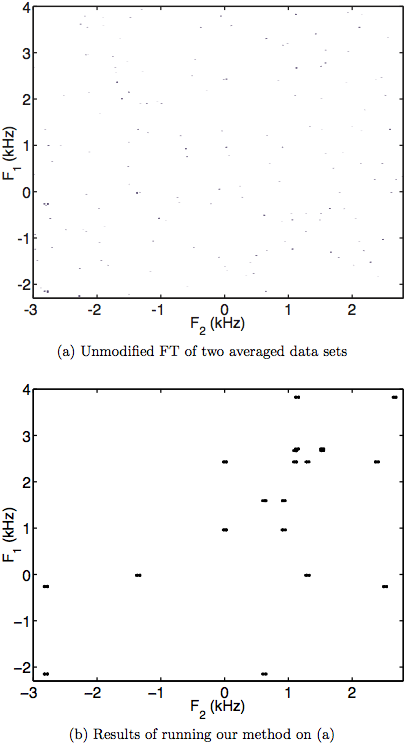
Locating Carbon Bonds from INADEQUATE Spectra using Continuous Optimization Methods and Non-Uniform K-Space Sampling
By Sean Colin Watson
May 2011
The 2-D INADEQUATE experiment is a useful experiment for determining carbon structures of organic molecules known for having low signal-to-noise ratios. A non-linear optimization method for solving low-signal spectra resulting from this experiment is introduced to compensate. The method relies on the peak locations defined by the INADEQUATE experiment to create boxes around these areas and measure the signal in each. By measuring pairs of these boxes and applying penalty functions that represent a priori information, we are able to quickly and reliably solve spectra with an acquisition time under a quarter of that required by traditional methods. Examples are shown using the spectrum of sucrose. The concept of a non-uniform Fourier transform and its potential advantages are introduced. The possible application of this type of transform to the INADEQUATE experiment and the previously explained optimization program is detailed.
|
 |
Read the entire thesis here.
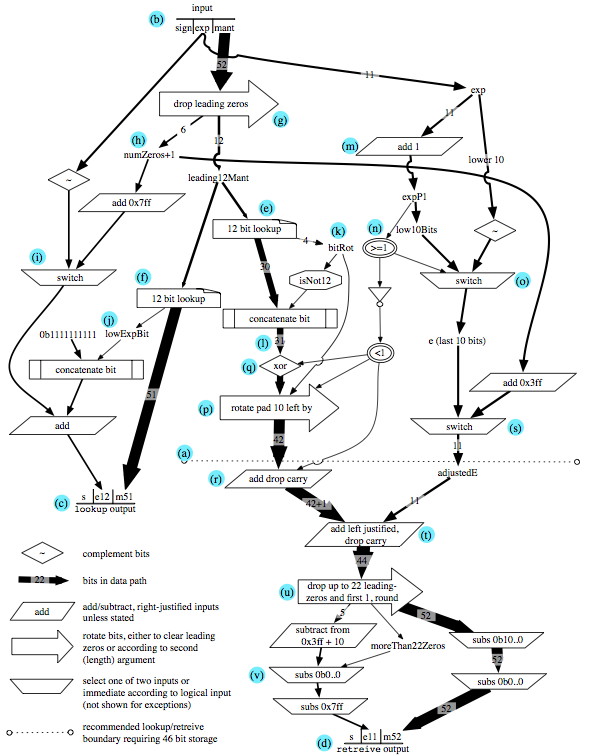 |
Elementary Function Evaluation Using New Hardware Instructions
By Anuroop Sharma
August 2010
In this thesis, we present novel fast and accurate hardware/ software implementations of the elementary math functions based on range reduction, e.g. Bemer’s multiplicative reduction and Gal’s accurate table methods. The software implementations are branch free, because the new instructions we are proposing internalize the control flow associated with handling exceptional cases.
These methods provide an alternative to common iterative methods of computing reciprocal, square root and reciprocal square root. These methods could be applied to any rational-power operation. These methods require either the precision available through fused multiply-accumulate instructions or extra working precision in registers. We also extend the range reduction methods to include trigonometric and inverse trigonometric functions.
The new hardware instructions enable exception handling at no additional cost in execution time, and scale linearly with increasing superscalar and SIMD widths. Based on reduced instruction, constant counts, and reduced register pressure we would recommend that optimizing compilers always in-line such functions, further improving performance by eliminating function-call overhead.
On the Cell/B.E. SPU, we found an overall 234% increase in throughput for the new table-based methods, with increased accuracy.
The research reported in the thesis has resulted in a patent application [AES10], filed jointly with IBM.
Read the entire thesis here. |
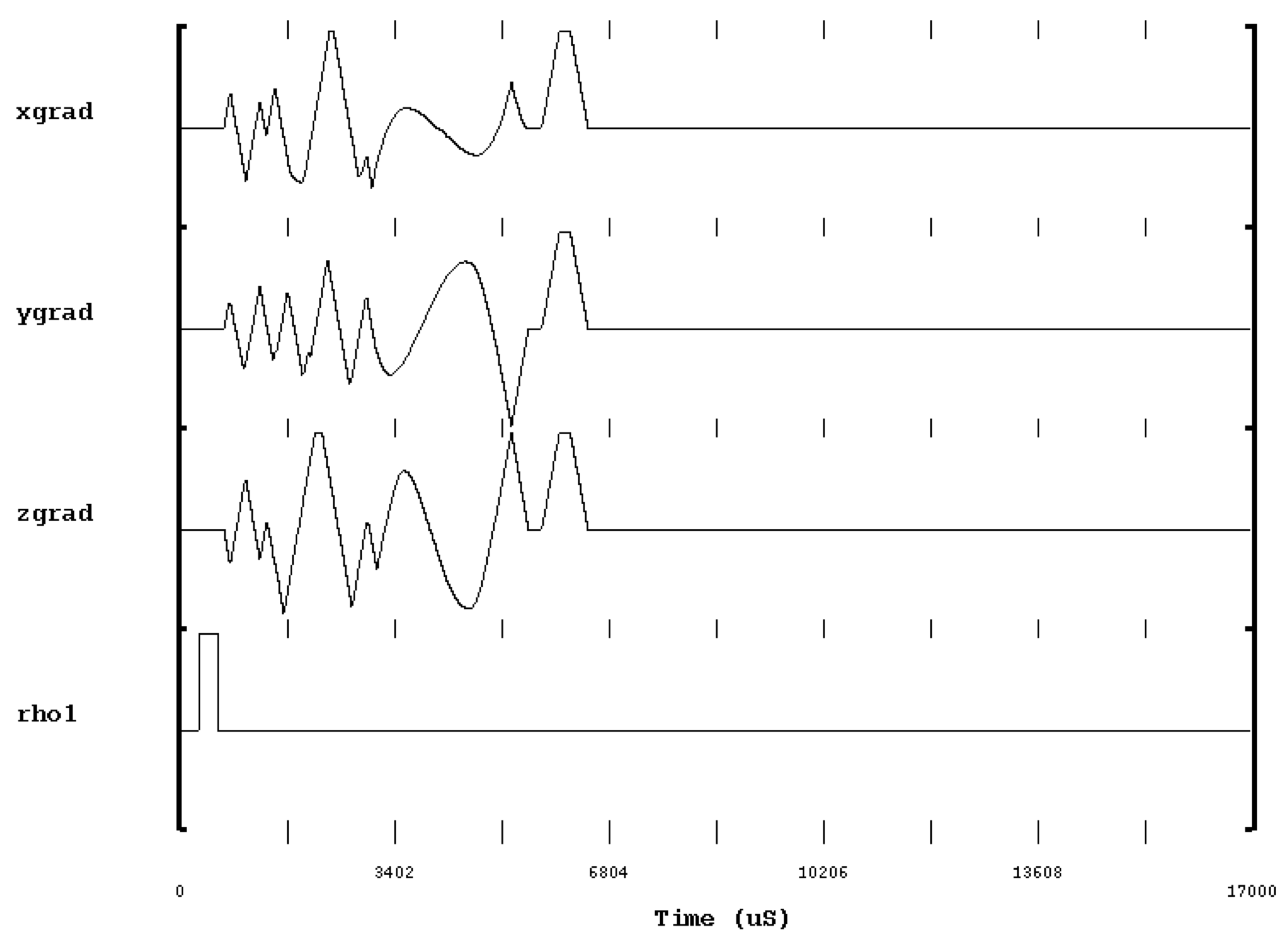
Implementation of DURGA: A Pseudo-Random, non-Cartesian Sampling Scheme
By Paul Polak
May 2009
One important topic in Magnetic Resonance Imaging (MRI) is a desire for faster and more efficient scanning, with an elimination, or at least minimization, of artifacts in the resulting image. Reducing patient discomfort, increasing scanner throughput, difficulties in imaging dynamic elements (cardiovascular system), and minimization of movement artifacts motivate faster scan times. To this end, more complicated and mathematically intense sampling strategies have been developed which either under-sample or ignore portions of k-space. These missing samples manifest themselves as specific artifacts indicative of the sampling strategy and the amount of under-sampling.
Durga uses pseudo-random, volumetric and velocity insensitive k-space trajectories, which are derived from second-order cone optimization problems [2]. Under-sampling a random trajectory results in artifacts which resemble incoherent noise [19] instead of aliased images. Velocity insensitive trajectories do not require rewinders to balance first or higher order moments. Further, volumetric or 3D k-space sampling strategies can choose to ignore slice select rewinders by beginning and terminating sampling readout at the centre of k-space, interspersed with a finite time around the RF pulse. These combine to increase the sampling duty-cycle, resulting in increased efficiency and decreased imaging time.
The initial experiments described in this thesis indicate Durga’s potential for use in various ultra-fast MR applications, in particular time-sensitive, high contrast applications, where the presence of random, white-noise does not represent a major detriment to the images. In particular, the efficacy of magnetic resonance angiography (MRA), albeit in simulated, static experiments, is investigated with positive results.
This dissertation is intended to be a summary of the implementation of Durga on a 3.0T GE MRI system, required in the fulfillment of a M.A.Sc in Biomedical Engineering from McMaster University. Included is basic MR theory, overview of various sampling strategies and techniques, outline of the hardware and software tools, results and discussion.
|
 |
Read the entire thesis here.
Model-Based Tissue Quantification from Simulated
Partial k-Space MRI Data
By Mehrdad Mozafari
July 2008
Pixel values in MR images are linear combinations of contributions from multiple tissue fractions. The tissue fractions can be recovered using the Moore-Penrose pseudo-inverse if the tissue parameters are known, or can be deduced
using machine learning. Acquiring sufficiently many source images may be
too time consuming for some applications. In this thesis, we show how tissue
fractions can be recovered from partial k-space data, collected in a fraction of
the time required for a full set of experiments. The key to reaching significant
sample reductions is the use of regularization. As an additional benefit, regularizing the inverse problem for tissue fractions also reduces the sensitivity
to measurement noise. Numerical simulations are presented showing the effectiveness of the method, showing three tissue types. Clinically, this corresponds
to liver imaging, in which normal liver, fatty liver and blood would need to be
included in a model, in order to get an accurate fatty liver ratio, because all
three overlap in liver pixels (via partial voluming).
|
 |
Read the entire thesis here.
 |
Explicitly Staged Software Pipelining
By Wolfgang Thaller
August 2006
Software Pipelining is a method of instruction scheduling where loops
are scheduled more efficiently by executing operations from more than one
iteration of the loop in parallel. Finding an optimal software pipelined schedule
is NP-complete, but many heuristic algorithms exist.
In iteration i , a software pipelined loop will execute, in parallel, "stage"
1 of iteration i , stage 2 of iteration i - 1 and so on until stage k of iteration
i - k + 1.
We present a new approach to software pipelining based on using a
heuristic algorithm to explicitly assign each operation to its stage before the
actual scheduling.
This explicit assignment allows us to implement control flow mechanisms that are hard to implement with traditional methods of software pipelining, which do not give us direct control over what stages instructions are assigned to.
Read the entire thesis here. |
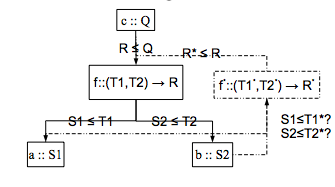
HUSC Language and Type System
By Gordon J. Uszkay
June 1, 2006
HUSC is a high level declarative language designed to capture the relations and
properties of a complex system independently of implementation and platform. It is
intended for use in Coconut (COde CONstructing User Tool), a pro ject at McMaster
University to create a new development environment for safety-critical, computationally intensive domains such as medical imaging. The language is intended to provide
an interface that is comfortable for use by scientists and engineers, while providing the
benefits of strong, static type analysis found in functional programming languages.
HUSC supports type inferencing using constraint handling rules, including both
predefined, parameterized shapes and an arbitrary number of additional properties or
constraints called attributes. Each attribute class provides its own type inferencing
rules according to the HUSC attribute class definition structure. Multiple implementations of an operator or function can each specify a specialized type context,
including attributes, and be selected based on type inferencing. The HUSC system
creates a typed code hypergraph, with terms as nodes and edges being all of the
operator or functions implementations that are satisfied in the type context, which
can be used as the basis for an optimizing compiler back end.
We present here the HUSC language and type system, a prototype implementation
and an example demonstrating how the type inferencing may be used in conjunction
with the function joins to provide a good starting point for code graph optimization. It
also includes a number of observations and suggestions for making the transition from
prototype to useable system. The results of this work are sufficient to demonstrate
that this approach is promising, while highlighting some difficulties in producing a
robust, practical implementation.
|
 |
Read the entire thesis here.